PRECIOS COMUNIDAD DE MADRID - Parametros y Datos
¿Qué datos necesitamos? ¿De qué depende el precio de las viviendas?
Para saber con qué datos de entrada entrenaremos a nuestro sistema de predicción es importante saber que variables consolidan un precio. Anotemos los más básicos:
- Longitud.
- Latitud.
- Altura.
- Tipo de Vivienda.
- Superficie.
- Antigüedad.
- Número de Baños.
- Número de Ascensores.
- Número de Dormitorios.
- Tipo de Inmueble.
- Trastero.
- Número de Plazas de Garaje.
- Aire acondicionado.
En principio estos son los más obvios. Queda claro que:
- Viviendas de tipo unifamiliaries aisladas (chalet) son más caras que un piso de un edificio de las mismas proporciones.
- A mayor superficie mayor precio.
- El precio de una casa de iguales proporciones pero un piso más alto encarece.
- Viviendas más antiguas son más baratas.
- Etc.
Pero faltan otras menos intuitivas:
- Nivel de delicuencia en el barrio donde se ubica.
- Equipamiento de la zona: zonas verdes, servicios escolares, médicos, etc.
- Cercanía a centros comerciales.
- Cercanía a supermercados.
- Cercanía a boca de metro.
- Número de bocas de metro cercanas.
- Eficiencia energética.
- Vistas al retiro o casa de campo.
- Etc.
Más aún, podrían existir parametros que nunca se nos hubieran imaginado:
- Supongamos que hay una zona que “está de moda” en Madrid, por ejemplo porque es una zona donde han abierto museos de prestigio y reúne artistas de alto valor adquisitivo. Sabemos que la zona tiene precios altos frente a otras zonas colindantes pero no sabemos qué “peso” tiene frente a otros parámetros.
- Supongamos que las vistas son privilegiadas como un ático al retiro.
Finalmente el sistema predictivo debe cargarse con otros posibles parámetros que no creemos están relacionados pero a los que la red puede generar cierto peso:
Supongamos que añadimos el color de la fachada de la vivienda. El proceso será capaz de predecir si hay algún color que encarezca la vivienda aportando más peso a unos colores y menos a otros. ¿Es imposible? Un caso real de ello es el de WallMart: cuando cruzaron épocas de huracanes con ventas de ciertas tartas en sus supermercados vieron que estas se disparaban. Un sistema de predicción entrenado con ese “ilógico” parámetro de entrada (epoca de huracán) hubiera predicho ventas mayores en esos períodos.
Para nuestro estudio tomamos solo 17 parametros muy evidentes aunque no se descarta añadir más en un futuro. Los datos han sido extraídos de los principales portales inmobiliarios simulando la navegación mediante software para la zona de la Comunidad de Madrid. Se han obtenido 36.827 viviendas con este nivel de detalle (17 variables).
Pero, ¿son rigurosos esos datos? ¿cómo afecta al sistema predictivo?
Los datos recogidos en las web pueden fluctuar según el precio que considere el usuario, no son precios de tasación ni cerrados de compra y venta. Así habrá que tener en cuenta que el sistema aprenderá sobre un grupo de precios donde el usuario pone el precio, es decir, aprende a predecir precios que se expondrían en este tipo de webs.
Optimización de Datos.
Antes de nutrir nuestra red neuronal con todos los datos debemos filtrarlos. Veamos una gráfica de precios:
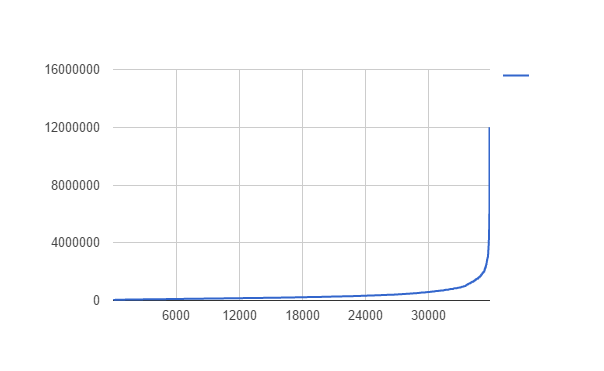
Podemos observar que hay algunos datos que se desvían demasiado del resto que filtraremos ya sea por un error tipográfico en las webs desde donde se añadieron o porque no queremos que el sistema “aprenda” con estos datos tan aislados
Del mismo modo también filtraremos en otros parámetros para "igualar" sus valores:
- Antigüedad >=1.900 y <=2016 (año)
- Precio >=40.000 y <=2.000.000 (€)
- Superficie >=30 y<=1200 (m2)
- Altura (~planta) >=-1 y <=24
- Número de Baños <=10
- Número de Dormitorios <=10
- Número de Plazas de Garaje <=2
- Ascensor <=1
Chequeemos de nuevo la gráfica de Precios. Podemos ver que el filtro hace que los datos sean más homogéneos:
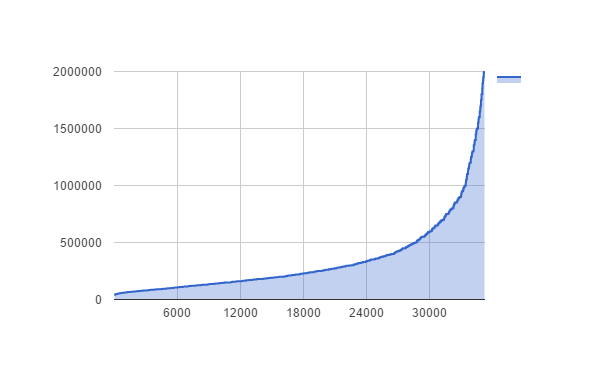
Así nos quedamos con 35.252 viviendas homogéneas donde un grupo de un 75% nos servirá para entrenar y así predecir el 25% restante.
Veamos un zoom sobre la Comunidad de Madrid representando los precios en un mapa de calor y en otro de barras en perspectiva:
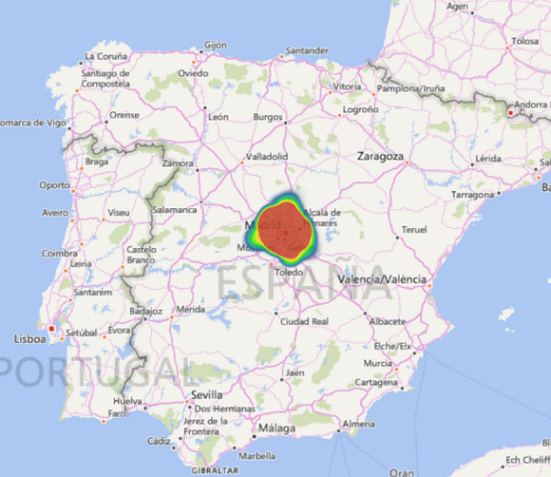
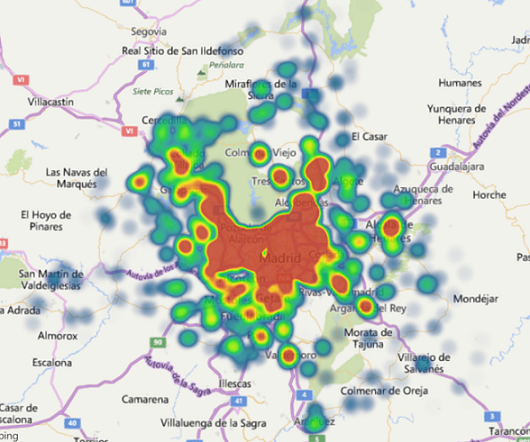


Ya tenemos los datos acotados, con ellos podemos montrar una estructura de red neuronal como la que se muestra en el siguiente capítulo